

7月27-30日,2017ChinaJoy(中国国际数码互动娱乐展览会)在上海新国际博览中心如期举办,CGDC(中国游戏开发者大会)也在嘉里中心同期召开。7月28日下午,AMD资深软件工程师解庆春受邀为CGDC奉上了题为《基于VR全景直播需求的实时全景拼接技术与方案》的精彩演讲,从多个层面为与会者介绍了AMD的实时全景拼接方案Loom及其背后的技术。下文为AMD工程师的演讲内容整理,希望能够对全景内容开发者有所帮助。
借VR东风 全景视频再获关注
近两年VR概念火爆,投资界对此也非常信赖,市面上出现了好多VR厂商。他们都认为VR(虚拟现实)的广阔市场前景,说是下一个风口。于是市面上很快出现了各式各样的VR头盔硬件,但是目前VR存在的最大问题之一是缺乏内容。全景相机拍摄的内容适合给VR头盔使用,用户借助头盔设备,可以从镜头的角度获得360度的全景,使用户感到画面逼真,具有沉浸感。从新石器时代的洞穴壁画到当代的IMAX及VR/AR体验,都可以看出来人们非常享受360度环境下的艺术体验。
借助VR发展的东风,360度全景视频重新受到关注,也越来越普及。开发者们在想,除了离线视频——离线合成拼接好保存下来的全景视频文件,实时播放或者转播方面能不能引入全景呢?这种需求很早就有,但实时拼接一直没有实现,因为受到硬件计算资源的限制不能提供实时性,现在强大的计算资源(包括多核心CPU,FPGA,GPU异构加速器,大显存等),足以支撑高质量实时视频拼接。所以,今天我给大家讲解一下360度全景视频实时拼接的技术。
首先,我们从技术层面了解一下什么是全景视图,全景视图是指在一个固定的观察点,能够提供水平方向上360度,垂直方向上180度的自由浏览,简化的全景只能提供水平方向360度的浏览。
其次,我们再了解一下什么是全景拼接,全景图像拼接(Image Stitching)是一种利用实景图像组成全景空间的技术,将多幅图像拼接成一幅360度大尺度全景视图。
近些年,全景相机有了一个大爆发,市面上出现了各种各样的360度全景相机,不同的相机面向不同的市场及不同消费者。每个全景相机的镜头数量也不一样。如,双目的理光相机,四目的得图相机,surround360 方案支持17目,而AMD loom方案提出最大到31目,行业里经常用Rig(阵列)这个词来代表多个镜头组装的全景相机。如下图所示:

使用过以上某种头盔并且感受过高分辨率的360度全景视频用户,可能会认为360度拼接技术上已经是一个基本上被解决了的问题。实际上并非如此。当然过去这几十年的算法先驱们所做出的成绩值得被肯定,因为他们的努力已经解决了很多关于全景视频拼接的问题。但是从软硬件层面看还有许多问题待突破。
硬件层面,很多问题也还有待改进,比如全景相机的能耗问题、发热问题、全局快门同步问题、相机镜头畸变工艺问题、相机防抖解决问题,更多的相机数量带来高带宽传输的问题,更多隙缝和隙缝缝合的计算延迟等问题。
软件层面,全景相机目前软件拼接的理论或者框架已经相对成熟,框架基本上都是采用的autostitch 2007年的框架,存在的问题是数据采集和传输的带宽延迟问题,拼接流程所需处理时间较长等。
硬件方面的问题只能借助工艺和材质尽可能的减少拼接误差。比如,镜头畸变只能通过材质和工艺尽可能减少。采集时的相机同步也可以借助锁相同步硬件来处理,发热和功耗通过设计更好的IC来解决等。
软件拼接层面,我们知道大多的图像处理算法,具有天然的数据并行性,适合在GPU作为异构加速部件来完成处理。GPU自身所集成的几千个流处理器可以使多数图像处理的速度提高一到几个数量级,大大减少了每帧图片的处理时间,因此也使多个相机拍摄的视频可以实时合成,实时输出。此外,如果借助于GPU的传输通道和带宽,完成采集到的数据流直接进入GPU。
实时拼接有难度 AMD Loom来助力
AMD根据自家GPU硬件和在OpenCL异构计算方案的技术优势,也为实时拼接领域提出了自己的一套360度实时视频拼接方案,名字为Loom,并将其进行了开源。Loom为影视级VR视频体验提供创造性的动力,最大可能的缩短视频拼接时间延迟,使高质量的全景直播成为可能,同时使高质量360度视频的创作过程更加简化,帮助影视内容艺术创作者释放更多的精力在独特的内容创作上面。
首先,我们看一下AMD LOOM方案的整个框架。我们从下往上分层介绍:
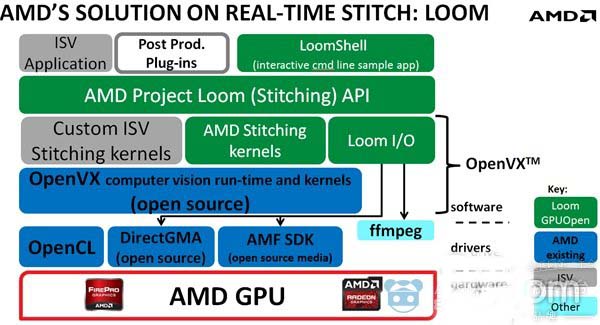
首先是计算部件,在其上是异构计算平台OpenCL,驱动层面提供支持的DirectGMA库和完成多媒体音视频编解码的AMF库。OpenCL是底层开发基础库,帮助上层视觉处理函数完成加速。DirectGMA技术适合通过采集卡实时采集并进入GPU拼接的系统,同时需要采集卡厂商驱动的支持。完成采集卡采集到的视频流数据直接传输到GPU的显存,绕开CPU和内存,减少了数据传输的延迟和带宽浪费。AMF SDK 主要完成视频采集、视频拼接后期的工作,比如音视频的融合,H.264软编码后输出,减少存储空间和传输带宽。
第三层是基于OpenCL的计算视觉加速库OpenVX。OpenVX和OpenCL都是开源组织khronos提出的标准,仅仅是标准接口,有不同的vendor来根据自家的硬件特性来实现,当然也可以根据自己硬件和自己的想法在这些标准接口的基础上再做一些扩展。
第四层是在OpenVX等视觉加速库的基础上,完成视频拼接算法流程每一步需要的OpenVX kernel,实时视频拼接流程如图所示,每种算法通过一个或多个OpenVX kernel函数实现,以开发库的形式提供上层用户调用,比如CSC 颜色空间域转换kernel,透镜畸变矫正kernel,Blend 阶段的高斯金字塔和laplacian金字塔的创建kernel。此外该框架还对第三方提供OpenVX接口,如果第三方用户自己设计了新的拼接算法,可以在OpenVX的基础上,添加自己的算法kernel实现到Loom。
第五层是在根据拼接算法流程,对下层提供的kernel再一层封装,比如提供CSC接口,Warp 接口,seam find 接口等。供用户调用完成视频拼接或类似视频处理的应用。
最上层是利用Loom提供的stitch library,用户可以完成视频拼接工作,拼接后期处理工作,Loom自身为了调试和培训用户等,实现了一个命令行解析器,通过命令行的形式完成多张图片的拼接任务。第三方还可以开发出某种控件,供其他应用软件直接调用。
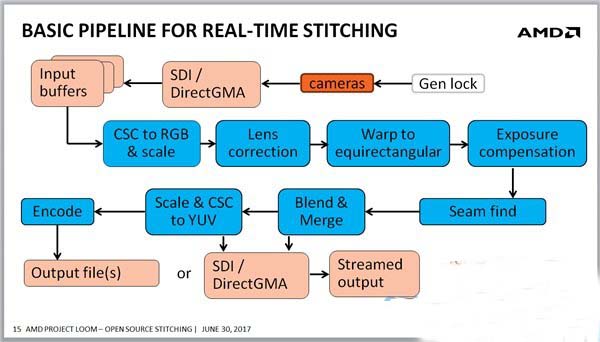
AMD Loom通过GPU异构加速方案和AMD 实现的OpenVX计算视觉加速库,使360度高质量的视频实时拼接成为可能。
AMD Loom可实时拼接多至24个4k x2k镜头、离线拼接多至31个8K x4K镜头拍摄到的画面。如果你恰巧已经是一位360视频开发者,可点击Radeon Loom Stitching Library on http://GPUOpen.com 下载Loom的beta版本。目前AMD中国团队正在和本地摄像机开发商合作,提供端到端的解决方案,届时会面向VR全景用户发布。
P.S. 此次AMD展位(E3馆S111)也首次展示了AMD Radeon Loom实时全景拼接技术支持的VR直播方案:展位部分环节通过全景相机ZCAM和戴尔Precision 7720移动工作站(装载AMD Radeon™ Pro WX 7100显卡)在新浪微博平台进行VR直播。想要围观该方案的朋友千万不要错过。